Generating Fake Conversations by fine-tunning OpenAI's GPT-2 on data from Facebook Messenger
Using Google Colab
One of the most interesting problems in NLP has always been human-like conversation and many are still considering passing the Turing Test as the holy grail of the field. In this post, I show how to use a state of the art model on your own data (I use my own messages sent on facebook) to generate (somewhat) realistic conversations.
In February 2019 OpenAI released information on their new state of the art language model which created a lot of buzz within the community. While few disagree the results they included are better than anything we’ve seen before (even if mainly because they made a bigger model combining recent advances), many were peeved that OpenAI only released a small pre-trained version of their model rather than the full one they generated examples with. Nonetheless, the small model is also very good, and due to nshepperd’s addition to their code, we can easily fine-tune it on our own data to easily generate (near-)state of the art results specific to whatever we want.
Since then people have been experimenting with the model, including some like the aforementioned nsheppered adding simple scripts allowing us to fine-tune the model on our data. In this post, I am going to describe how to use easily available tools like those scripts, Google Colab and Facebook’s Data Export option in order to create borderline realistic conversation snippets.
If you don’t have enough data on facebook, you should be able to easily export your conversation data from pretty much any other service and train on that. Better yet, you can combine data from different sources - as usual with machine learning, the more data you have the better.
You can follow in the colab here. Make sure to click Runtime> Change Runtime type> GPU (or TPU)
Code
We start with the imports
import os
import json
import random
import re
Then we clone my fork of nsheppered’s GPT finetuning repo - I’ve only made some small changes to it - mainly adding a couple of extra command line options for changing things like the learning rate and adding a stopping point. We also cd into it, and install the requirements and download the model.
!git clone https://github.com/Tenoke/gpt-2.git
cd gpt-2
!pip3 install -r requirements.txt
!sh download_model.sh 117M
Next, we need to download our facebook messages. Facebook explains how to do it here. Only select ‘messages’ and for the format select ‘json’. After it is ready you can either download the file by clicking download or by using Dev Tools. To do so open them with F12, go to sources, and click download (and then just cancel it), then find the entry starting with file.php, right click it and ‘copy as curl’ as in this screenshot
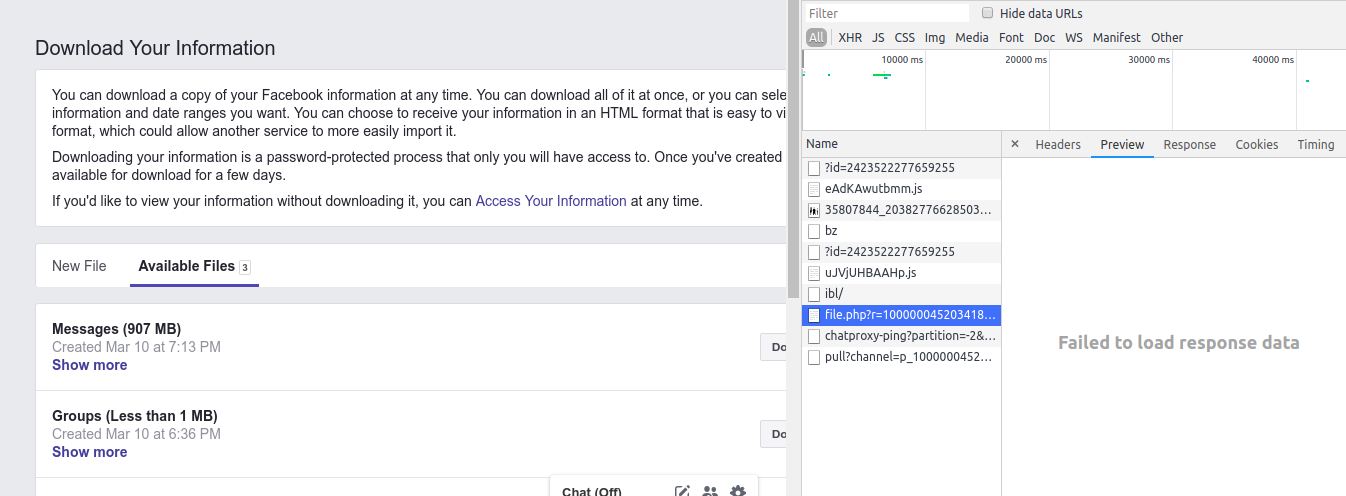 then just add ! in front of the command (to run it in colab) and
then just add ! in front of the command (to run it in colab) and --output fb-json.zip at the end to name the file.
` !curl –output fb-json.zip ` After that, we unzip the file and get a list containing all files with message data (as opposed to the other stuff that facebook includes in the zip)
!unzip fb-json.zip
files = []
for p, d, f in os.walk('messages/inbox'):
for file in f:
if file.endswith('message.json'):
files.append(f'{p}/{file}')
len(files)
You should see a non-zero number at this point if everything is going as planned. In my case 560.
I’ve also included a few functions - one to fix the encoding and escaping in facebook’s data, and two to detect cyrilic so I can exclude any chats I have not in English (this part would be irrelevant for most)
def fix_encoding(s):
return re.sub('[\xc2-\xf4][\x80-\xbf]+',lambda m: m.group(0).encode('latin1').decode('utf8'),s)
Now it is time to actually create a corpus from all those files. If you have a lot of data, you might want to do this in steps. There’s also a banned_names tuple where you can add any names you don’t want to appear in the corpus.
text_corpus = ''
banned_names = ('vladislav')
for file in files:
with open(file, 'r') as f:
try:
msgs = json.load(f)['messages']
msgs.reverse()
except:
pass
else:
if not any(bn in file for bn in banned_names):
for msg in msgs:
try:
content = fix_encoding(msg['content'])
to_add = f"({msg['timestamp_ms']}) {msg['sender_name']}: {content}\n"
text_corpus += to_add
except KeyError:
pass
print(file)
text_corpus += '\n\n'
We then save the data to a file, check how big the file is (14m in my case) and encode the data (unnecessary but it is faster if you do it before training).
with open('fb-cleaned.txt', 'w') as f:
f.write(text_corpus)
It is time to start trainning!
!PYTHONPATH=src ./train.py --dataset fb-cleaned.txt.npz --sample_every=250 --learning_rate=0.0001 --stop_after=251
!PYTHONPATH=src ./train.py --dataset fb-cleaned.txt.npz --sample_every=250 --learning_rate=0.001 --stop_after=751
!PYTHONPATH=src ./train.py --dataset fb-cleaned.txt.npz --sample_every=250 --learning_rate=0.0001 --beta=0.95 --stop_after=1251
At this point, we can see samples, although feel free to change the learning rate, beta or train for more cycles. The code so far takes under an hour to run for me but it depends on the size of your dataset among other things.
We need to first copy the new trainned weights.
!cp -r /content/gpt-2/checkpoint/run1/* /content/gpt-2/models/117M/
After which we can either let it generate chats on its own with
!python3 src/generate_unconditional_samples.py --top_k 40 --temperature 0.9
Or we can force it to give us chats with a specific person (or on a topic) by running
!python3 src/interactive_conditional_samples.py --top_k 40 --temperature 0.9
And then giving it something like (137378602389) Ioannis Agathocleous: hi in the interactive prompt to get a chat with that person.
Here are some samples. Some are better than others
(134972898517) Ioannis Agathocleous: lol sounds better to me
(1349728992965) Svilen Todorov: lol if its fine you wont be able to be a middle aged man without pay
(1349680771216) Ioannis Agathocleous: but thats kind of what you were meant to think
(1349680826981) Ioannis Agathocleous: probs not
(13496808663733) Svilen Todorov: hah
(13496808683320) Ioannis Agathocleous: u know anyone else that can pay me in the end
(13496808843212) Ioannis Agathocleous: i heard someone pay them last year and i want to buy a house
(1349680884843) Svilen Todorov: yeh, well, its good to me as i can get some money with them
(13496809066473) Svilen Todorov: i am
(1349680951765) Svilen Todorov: and i wont have to bother with taxes and whatnot
(1349680951723) Svilen Todorov: they shouldnt do things that are worth it
(1349680997574) Ioannis Agathocleous: thats great
(134968099728) Ioannis Agathocleous: but its a long process
(134968099818) Ioannis Agathocleous: it doesnt matter how your kids loan is
(134968099824) Ioannis Agathocleous: just pay someone
(1349680986601) Svilen Todorov: dunno if it wouldnt matter
(1349680997829) Ioannis Agathocleous: if its going to be good Id expect them to do that
(1349680999997) Svilen Todorov: but yeh, thats kind of what i said
(134968099961) Ioannis Agathocleous: well it doesnt matter, its the thing
The conversations usually make sense for the person. We discuss things like sleeping problems, how we are and what we are doing often so you get stuff like:
(15191201253003) Svilen Todorov: haha
(1519120163882) Svilen Todorov: what are you up to
(1519120147982) Svilen Todorov: dunno
(1519120174335) Svilen Todorov: whats going on
(1519120175033) Anna Gaydukevich: I got a present on the desk!
(1519120187017) Anna Gaydukevich: how’s it going?
(1519122123459) Svilen Todorov: alright
(15191212141350) Svilen Todorov: how are you feeling
(1519122127646) Svilen Todorov: havent been out at all
(1519121366360) Anna Gaydukevich: yeah sounds good
(1519121387453) Svilen Todorov: hahah
(15191214178936) Svilen Todorov: im on my way back
(15191214278912) Anna Gaydukevich: how was your trip?
(1519121428989) Svilen Todorov: im still in the office
(1519121581623) Svilen Todorov: 😀
(15191218780009) Anna Gaydukevich: alright sounds good
(1519121887000) Svilen Todorov: i slept like 5 hours
(1519121833743) Svilen Todorov: was too hard to sleep tonight
(1519121898425) Svilen Todorov: 😀
(1519290525900) Lisa Martins: what are your plans?
(1519290547803) Svilen Todorov: they have to do something in the office for an hour
(1519290549909) Svilen Todorov: but i dont really sleep much
(1519290556640) Svilen Todorov: so it’s a bit more fun
(1519290563817) Svilen Todorov: so it wont be too bad
(1519296376813) Anna Gaydukevich: yeah i might try’
(152665502433) Svilen Todorov: cool, nice!
(152665505561) Svilen Todorov: did u check your messages
(1526655031868) Eliza Beth: I’ve seen him before. This isn’t the main one though. Maybe the one of you’ll find out.
(152665506496) Svilen Todorov: its more like what I saw at my friend’s place and he was kind of curious so it might’ve been like some sort of a catch up, with some of the others’ friends with a nice airheaded man
(1526655080653) Eliza Beth: Jeez!
(1526655087642) Eliza Beth: He says it’s the only thing you’ve read yet lol
(1526655089792) Svilen Todorov: well it’s like a few people in my area, so i reckon thats where you’re going
(1526655053361) Eliza Beth: I assume he might buy it
(1526655797371) Svilen Todorov: but you can still look for it now tho
(15266557573782) Svilen Todorov: I dont know though
(152665582321) Svilen Todorov: i reckon the first 2 days in a row wouldve gotten more in the first few days
(1526658692365) Svilen Todorov: and you can buy it now if you only just know the local people
(1526655791832) Svilen Todorov: tho he seems to think the local girl is the most famous person here because she’s probably the best friend, so not sure whether she’ll buy money for that
(1526655871168) Eliza Beth: Omg dude how was work?
(1526655781360) Eliza Beth: I think it’s the same as the first few months. It was fairly fun
(1526655892792) Svilen Todorov: but you’ll be a bit more able to pick up for later
(1526656997775) Svilen Todorov: i was telling people what you can do to get a flat or whatever
However, it sometimes makes understandable but funny mistakes. E.g. my girlfriend has ‘gay’ in her name so it came up with this
(1596993813136) Svilen Todorov: hey how was ur day
(1596993881281) Svilen Todorov: just came in the morning, and the guy came, and we were still sitting on the couch
(1596993881783) Svilen Todorov: so was pretty good
(1596993913019) Svilen Todorov: and then i got to bed
(1596993945750) Svilen Todorov: wasnt too bad even a bit after i went to bed
(1596993957122) Anna Gaydukevich: oh god thats the good part of me and me being gay
(1596993963304) Svilen Todorov: well not your fault
(1596993968954) Anna Gaydukevich: just felt kinda shit
(1596994070202) Svilen Todorov: like i just fell asleep so you didnt know what I would’ve been doing with me
(1596994075337) Svilen Todorov: haha i guess there was a moment in it, when someone came to ask me if i wanted a drink
(1596994119171) Svilen Todorov: so i told her that i am gay
(1596994135885) Svilen Todorov: that was weird
(1596994155756) Anna Gaydukevich: lol
(1596994176836) Anna Gaydukevich: but i can’t believe it
(1596994177861) Anna Gaydukevich: 😀
(1596994177563) Anna Gaydukevich: are you gay?
(1596994179040) Anna Gaydukevich: not my fault
(1596998641459) Svilen Todorov: dunno that I have a different level in most ways
(1596998646174) Anna Gaydukevich: oh yup
(1596994186636) Anna Gaydukevich: why do you think i am more of a gay guy than a gay guy
(1596998742412) Anna Gaydukevich: haha
(1596998770044) Svilen Todorov: seems like a lot of gay guys are gay’
It can also get creepy, for example in this conversation it generated with a friend of mine who passed away a few months ago
(134914376916) Sam Rendall: yeah definitely the next 5 days when I go home I would be super bad, not so much
(134914382811) Sam Rendall: well yeah, I didnt go and still went home and I can take that out too :D
(134915443033) Sam Rendall: yes just keep in the office that takes you up
(134915443939) Svilen Todorov: you will do
(134915445710) Svilen Todorov: its like 8-9 hours in a row
(134915447500) Sam Rendall: ok cool
(134915447700) Sam Rendall: yeah that’s sweet
(134915448937) Svilen Todorov: cool, i hope that you’re still alive
(134915457569) Svilen Todorov: but i have to go home to smoke in the morning after i went by and take your stuff
(134915459816) Sam Rendall: not bad for you
(134900491569) Svilen Todorov: and i’m gonna stay on the couch where you will be sleeping in the morning before coming
(13490049834) Sam Rendall: ohaha yeah :P
(1349004961272) Svilen Todorov: ugh
(134900496518) Sam Rendall: so much more of your body still hurts than mine
(1349008060178) Svilen Todorov: damn
(1349008171520) Svilen Todorov: that sounds shit
(13490092616) Sam Rendall: its a fucked up thing, not as fast of an idea
(1349009693548) Sam Rendall: my stomach hasnt been hurting to this point
Conclusion
The conversations look okay, though sometimes they are less coherent. It is clearly learning useful stuff - the timestamps generally go up, the conversations are relevant to the people in them, and so is the structure. Training it with more data would also definitely help.
Another way to make it produce slightly better results is to finetune it in the end on the chat from a specific person before generating conversations with them (I’ve added the relevant code to the colab).
We haven’t gotten anywhere near passing the Turing Test but I suspect that if you hook this up to facebook’s API to respond for you, it might take a while for some people to figure it out.